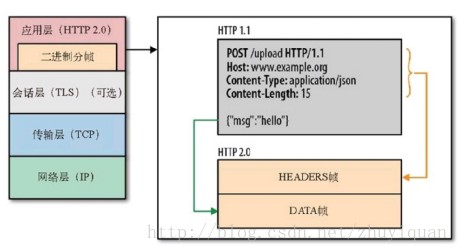
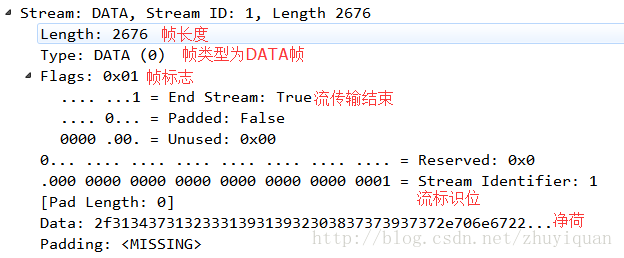
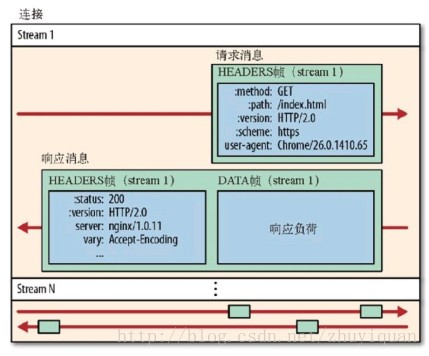
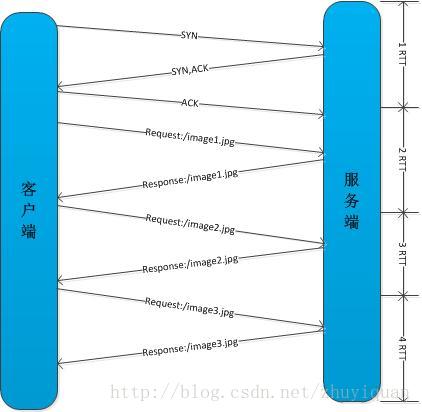
HTTP协议的内容协商
一、起因
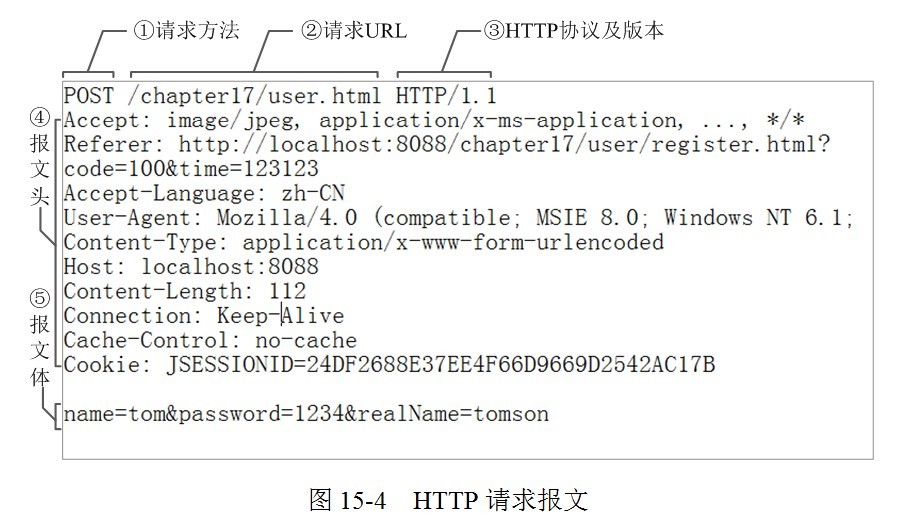
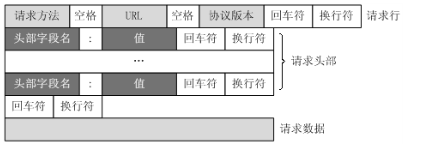
我们在日常的抓包过程中经常可以看到以Accept开头的请求首部,比如:Accept-Language 有一个q值,肯定有人好奇在HTTP规范中为什么要定义这个q值;还有在响应首部有一个名为Vary的首部,这个首部又有什么意义?如图所示:
 本文记录我对 Vary 的一些研究,其中就包含这些问题的答案。
本文记录我对 Vary 的一些研究,其中就包含这些问题的答案。
二、内容协商(两种方式)
一种是服务端把文档可用版本列表发给客户端让用户选,这可以使用 300 Multiple Choices 状态码来实现。这种方案有不少问题,首先多一次网络往返;其次服务端同一文档的某些版本可能是为拥有某些技术特征的客户端准备的,而普通用户不一定了解这些细节。举个例子,服务端通常可以将静态资源输出为压缩和未压缩两个版本,压缩版显然是为支持压缩的客户端而准备的,但如果让普通用户选,很可能选择错误的版本。
所以 HTTP 的内容协商通常使用另外一种方案:服务端根据客户端发送的请求头中某些字段自动发送最合适的版本。可以用于这个机制的请求头字段又分两种:内容协商专用字段(Accept 字段)、其他字段。
首先来看 Accept 字段,详见下表:
| 请求头字段 |
说明 |
响应头字段 |
| Accept |
告知服务器发送何种媒体类型 |
Content-Type |
| Accept-Language |
告知服务器发送何种语言 |
Content-Language |
| Accept-Charset |
告知服务器发送何种字符集 |
Content-Type |
| Accept-Encoding |
告知服务器采用何种压缩方式 |
Content-Encoding |
例如客户端发送以下请求头:
Accept:*/*
Accept-Encoding:gzip,deflate,sdch
Accept-Language:zh-CN,en-US;q=0.8,en;q=0.6
表示它可以接受任何 MIME 类型的资源;支持采用 gzip、deflate 或 sdch 压缩过的资源;可以接受 zh-CN、en-US 和 en 三种语言,并且 zh-CN 的权重最高(q 取值 0 – 1,最高为 1,最低为 0,默认为 1),服务端应该优先返回语言等于 zh-CN 的版本。q值的范围从0.0~1.0(1.0优先级最高)
浏览器的响应头可能是这样的:
Content-Type: text/javascript
Content-Encoding: gzip
表示这个文档确切的 MIME 类型是 text/javascript;文档内容进行了 gzip 压缩;响应头没有 Content-Language 字段,通常说明返回版本的语言正好是请求头 Accept-Language 中权重最高的那个。
三、vary的由来
有时候,上面四个 Accept 字段并不够用,例如要针对特定浏览器如 IE6 输出不一样的内容,就需要用到请求头中的 User-Agent 字段。类似的,请求头中的 Cookie 也可能被服务端用做输出差异化内容的依据。
由于客户端和服务端之间可能存在一个或多个中间实体(如缓存服务器),而缓存服务最基本的要求是给用户返回正确的文档。如果服务端根据不同 User-Agent 返回不同内容,而缓存服务器把 IE6 用户的响应缓存下来,并返回给使用其他浏览器的用户,肯定会出问题 。
所以 HTTP 协议规定,如果服务端提供的内容取决于 User-Agent 这样「常规 Accept 协商字段之外」的请求头字段,那么响应头中必须包含 Vary 字段,且 Vary 的内容必须包含 User-Agent。同理,如果服务端同时使用请求头中 User-Agent 和 Cookie 这两个字段来生成内容,那么响应中的 Vary 字段看上去应该是这样的:
Vary: User-Agent, Cookie
也就是说 Vary 字段用于列出一个响应字段列表,告诉缓存服务器遇到同一个 URL 对应着不同版本文档的情况时,如何缓存和筛选合适的版本。
不过查看:RFC 的vary头的例子就是 Vary: accept-encoding, accept-language ,可见accept-*也可以放在vary中。cache的唯一性只取决于request的vary里指定的headers。也就是从RFC 的文本来看,http设计上vary/cache机制和内容协商机制是正交的。
大白话:就是说 缓存机制 看的就是 vary,vary 里面不仅有User-Agent, Cookie字段,也可以有accept-* 字段,用来标记区分缓存。
关于vary 里面的 accept-encoding,比较特殊。第一,(按道理)压缩并不改变真正的内容,所以稍微聪明点的proxy就可以自行处理而不影响cache。第二,新版spec好像要求所有client必须支持gzip。所以accept-encoding有没有就没什么关系了。但是其他accept头就不一样。如果要作为区分缓存的标记,必须在vary中写明。
举例来说:
web服务器添加响应首部Vary: Accept-Encoding 告知代理服务器根据客户端的请求首部Accept-Encoding缓存不同的版本,这样下次客户端请求同一资源时,根据Accept-Encoding选择相应的缓存版本响应。
其实我们还可以禁用中间实体的缓存功能解决该问题:
web服务器设置响应首部: Cache-Control: private
通常添加Vary首部的解决方案比较通用,因为我们还是希望充分利用中间实体的缓存功能的。
四、Nginx 和 SPDY
通常,上面说的这些工作,Web Server 都可以帮我们搞定。对于 Nginx 来说,下面这个配置可以自动给启用了 gzip 的响应加上 Vary: Accept-Encoding:
gzip_vary on;
用 curl 验证我博客的 js 文件,响应头如下:
jerry@www:~$ curl --head https://imququ.com/.../xx.js
HTTP/1.1 200 OK
Server: nginx
Date: Tue, 31 Dec 2013 16:34:48 GMT
Content-Type: application/x-javascript
Content-Length: 66748
Last-Modified: Tue, 31 Dec 2013 14:30:52 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "52c2d51c-104bc"
Expires: Fri, 29 Dec 2023 16:34:48 GMT
Cache-Control: max-age=315360000
Strict-Transport-Security: max-age=31536000
Accept-Ranges: bytes
可以看到,服务端正确输出了「Vary: Accept-Encoding」,一切正常。
但是用 Chrome 自带抓包工具看下,这个响应头却是这样:
HTTP/1.1 200 OK
cache-control: max-age=315360000
content-encoding: gzip
content-type: application/x-javascript
date: Tue, 31 Dec 2013 16:35:27 GMT
expires: Fri, 29 Dec 2023 16:35:27 GMT
last-modified: Tue, 31 Dec 2013 14:30:52 GMT
server: nginx
status: 200
strict-transport-security: max-age=31536000
version: HTTP/1.1
我的博客支持 SPDY/2 协议,用 Chrome 访问我博客会走 SPDY,所以上面的响应头看上有点不同寻常,例如字段名都变成了小写;多了 status、version 等字段,这些变化下次专门介绍(注:见「SPDY 3.1 中的请求 / 响应头」)。神奇的是尽管服务端没任何变化,但响应中的 Vary: Accept-Encoding 却不见了。
SPDY 规定客户端必须支持压缩,这意味着 SPDY 服务器可以直接启用压缩而不用关心请求头中的 Accept-Encoding 字段。下面这段来自 Nginx 支持的 SPDY/2 协议:
User-agents are expected to support gzip and deflate compression. Regardless of the Accept-Encoding sent by the user-agent, the server may select gzip or deflate encoding at any time. [via]
于是,对于支持 SPDY 的客户端来说,Vary: Accept-Encoding 没有用途,Nginx 选择直接去掉它,可以节省一点流量。curl 或其他不支持 SPDY 协议的客户端还是走 HTTP 协议,所以看到的响应头是常规的。
Nginx 的这个做法是否合适一直有争论,实际上并不是所有支持 SPDY 的 Web Server 都会这么做。例如即使通过 SPDY 协议访问 Google 首页的 js 文件,依然可以看到 vary: Accept-Encoding:
HTTP/1.1 200 OK
status: 200 OK
version: HTTP/1.1
age: 25762
alternate-protocol: 443:quic
cache-control: public, max-age=31536000
content-encoding: gzip
content-length: 154614
content-type: text/javascript; charset=UTF-8
date: Tue, 31 Dec 2013 23:23:51 GMT
expires: Wed, 31 Dec 2014 23:23:51 GMT
last-modified: Mon, 16 Dec 2013 21:54:35 GMT
server: sffe
vary: Accept-Encoding
x-content-type-options: nosniff
x-xss-protection: 1; mode=block
PS:Vary 在 IE 下有很多坑,使用时要格外小心。网上这部分文章比较多,例如 hax 早年写的 IE 与 Vary 头,可以点过去了解下。[但是看评价有很多踩得,不知道可信度怎么样,就当个参考思路吧]
参考
书籍:《HTTP权威指南》
屈屈的博文:https://www.imququ.com/post/vary-header-in-http.html