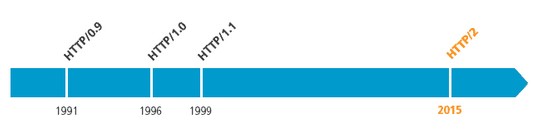HTTP协议是如今互联网与服务端技术的基石,HTTP协议的演进也从侧面反应了互联网技术的快速发展。这两天在准备一次关于HTTP1.1协议特性的技术分享过程中,顺便了解了下各版本HTTP协议的特点,在这里做个简单的总结。
维基百科:提到了http协议 各版本的 请求方法
HTTP defines methods (sometimes referred to as verbs) to indicate the desired action to be performed on the identified resource. What this resource represents, whether pre-existing data or data that is generated dynamically, depends on the implementation of the server. Often, the resource corresponds to a file or the output of an executable residing on the server. The HTTP/1.0 specification[13] defined the GET, POST and HEAD methods and the HTTP/1.1 specification[14]added 5 new methods: OPTIONS, PUT, DELETE, TRACE and CONNECT. By being specified in these documents their semantics are well known and can be depended on. Any client can use any method and the server can be configured to support any combination of methods. If a method is unknown to an intermediate, it will be treated as an unsafe and non-idempotent method. There is no limit to the number of methods that can be defined and this allows for future methods to be specified without breaking existing infrastructure. For example, WebDAV defined 7 new methods and RFC 5789specified the PATCH method.
HTTP协议到现在为止总共经历了3个版本的演化,第一个HTTP协议诞生于1989年3月。

1、HTTP 0.9
HTTP 0.9是第一个版本的HTTP协议,已过时。它的组成极其简单,只允许客户端发送GET这一种请求,且不支持请求头。由于没有协议头,造成了HTTP 0.9协议只支持一种内容,即纯文本。不过网页仍然支持用HTML语言格式化,同时无法插入图片。
HTTP 0.9具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。由此可见,HTTP协议的无状态特点在其第一个版本0.9中已经成型。一次HTTP 0.9的传输首先要建立一个由客户端到Web服务器的TCP连接,由客户端发起一个请求,然后由Web服务器返回页面内容,然后连接会关闭。如果请求的页面不存在,也不会返回任何错误码。
HTTP 0.9协议文档:
http://www.w3.org/Protocols/HTTP/AsImplemented.html
2、HTTP 1.0
HTTP协议的第二个版本,第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用。相对于HTTP 0.9 增加了如下主要特性:
- 请求与响应支持头域
- 响应对象以一个响应状态行开始
- 响应对象不只限于超文本
- 开始支持客户端通过POST方法向Web服务器提交数据,支持GET、HEAD、POST方法
- 支持长连接(但默认还是使用短连接),缓存机制,以及身份认证
3、HTTP 1.1
HTTP协议的第三个版本是HTTP 1.1,是目前使用最广泛的协议版本 。HTTP 1.1是目前主流的HTTP协议版本,因此这里就多花一些笔墨介绍一下HTTP 1.1的特性。
HTTP 1.1引入了许多关键性能优化:keepalive连接,chunked编码传输,字节范围请求,请求流水线等
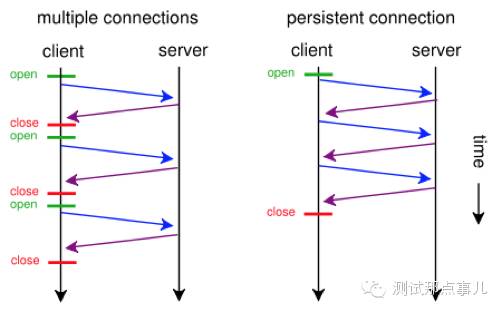
- Persistent Connection(keepalive连接)
允许HTTP设备在事务处理结束之后将TCP连接保持在打开的状态,一遍未来的HTTP请求重用现在的连接,直到客户端或服务器端决定将其关闭为止。
在HTTP1.0中使用长连接需要添加请求头 Connection: Keep-Alive,而在HTTP 1.1 所有的连接默认都是长连接,除非特殊声明不支持( HTTP请求报文首部加上Connection: close )
- chunked编码传输
该编码将实体分块传送并逐块标明长度,直到长度为0块表示传输结束, 这在实体长度未知时特别有用(比如由数据库动态产生的数据) - 字节范围请求
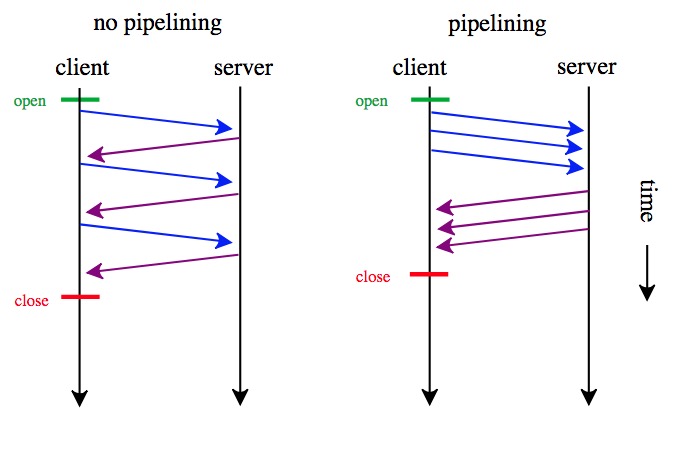
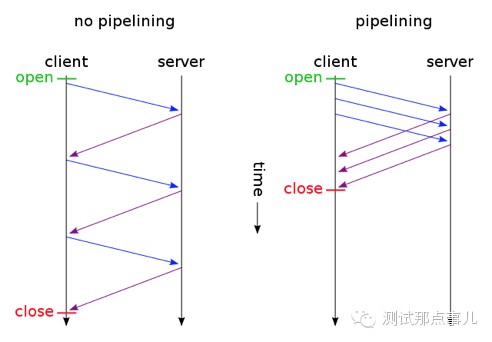
HTTP1.1支持传送内容的一部分。比方说,当客户端已经有内容的一部分,为了节省带宽,可以只向服务器请求一部分。该功能通过在请求消息中引入了range头域来实现,它允许只请求资源的某个部分。在响应消息中Content-Range头域声明了返回的这部分对象的偏移值和长度。如果服务器相应地返回了对象所请求范围的内容,则响应码206(Partial Content) - Pipelining(请求流水线)
A client that supports persistent connections MAY “pipeline” its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received.(摘自http://www.ietf.org/rfc/rfc2616.txt)
另外,HTTP 1.1还新增了如下特性:
- 请求消息和响应消息都应支持Host头域
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。因此,Host头的引入就很有必要了。 - 新增了一批Request method
HTTP1.1增加了OPTIONS,PUT, DELETE, TRACE, CONNECT方法 - 缓存处理
HTTP/1.1在1.0的基础上加入了一些cache的新特性,引入了实体标签,一般被称为e-tags,新增更为强大的Cache-Control头。
【上面提到了标准的请求方法总共就8种,外加后面提到的 patch方法 RFC5789】
4、HTTP 2.0
自从 RFC2616 即http1.1 协议正式发布
[http 1.1 协议正式发布 http://www.ietf.org/rfc/rfc2616.txt 发布时间:1999年3月
Network Working Group R. Fielding
Request for Comments: 2616 UC Irvine
Obsoletes: 2068 J. Gettys
Category: Standards Track Compaq/W3C
J. Mogul
Compaq
H. Frystyk
W3C/MIT
L. Masinter
Xerox
P. Leach
Microsoft
T. Berners-Lee
W3C/MIT
June 1999
Hypertext Transfer Protocol — HTTP/1.1
。。。。。。。
]
发布以来,一直是互联网发展的基石。HTTP协议也成为了可以在任何领域使用的核心协议,基于这个协议人们设计和部署了越来越多的应用。HTTP的简单本质是其快速发展的关键,但随着越来越多的应用被部署到WEB上,HTTP的问题慢慢凸显出来。今天,用户和开发者都迫切需要通过THHP1.1达到一种几近实时的响应速度和协议性能,而要满足这个需求,只在原有协议上进行修补是不够的。为了应对这些挑战,HTTP必须继续发展。HTTP工作组已经在2012年宣布要设计和开发HTTP2.0。HTTP2.0的主要目标是改进传输性能,实现低延迟和高吞吐量。
在HTTP2.0真正诞生之前,谷歌开发了一个实验性质的协议-SPDY,它定位于解决HTTP1.1中的一些性能限制,来减少网页的延时。自从2009年SPDY发布之后,这个协议得到了众多浏览器厂商和大型网站的支持,实践证明它确实可以很大幅度的提升性能,已经具备成为一个标准的条件。于是,HTTP-WG于2012年初提出要重在SPDY的一些实践基础上新设计和开发HTTP2.0,以期使数据传输具有更好的性能和更少的延时。SPDY是HTTP2.0的先驱,但二者并不能初略的划为等号,SPDY V2草案是HTTP2.0标准制定的起点,从此之后SPDY标准并没有停滞,而是在不断进化,它成为了HTTP2.0新功能及新建议的实验场,为HTTP2.0标准收纳的每一项建议,提供事前的测试和评估手段,总体来说SPDY比HTTP2.0更为激进。HTTP2.0协议版本发布历程如下:
- 2012年3月,HTTP2.0征集建议;
- 2012年11月,HTTP2.0第一稿;
- 2014年8月,HTTP2.0 draft-17和HPACK draft-12发布;
- 2014年8月,工作组最后征集HTTP2.0建议;
- 2015年2月,IESG批准HTTP2.0和HPACK草稿;
- 2015年5月,RFC 7540 (HTTP2.0) 和 RFC 7541 (HPACK) 发布;
在新的协议中,将会从根本上解决以往HTTP1.1版本中所做的“特殊优化”,将在这些解决方案内置在传输层中,使数据传输更加便捷和高效,如HTTP1.1及以前的版本中影响性能的很大一个问题,就是队首阻塞问题,在HTTP2.0中会将会通过新的组帧机制来解决这个问题,使连接可以多路复用,再通过压缩HTTP首部字段将协议开销降到最低。HTTP2.0不会改动HTTP语义,很好的继承以往版本的HTTP方法、状态码、URI及首部字段等核心概念,下面将对这些内容进行细致的描述。(本文最初发布于公司内网,外网原文地址:腾云阁—HTTP 2.0 简明笔记)
HTTP 2.0是下一代HTTP协议,目前应用还非常少。主要特点有:
- 多路复用(二进制分帧)
HTTP 2.0最大的特点: 不会改动HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念上一如往常,却能致力于突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。而之所以叫2.0,是在于新增的二进制分帧层。在二进制分帧层上, HTTP 2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。

HTTP 2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。 - 头部压缩
当一个客户端向相同服务器请求许多资源时,像来自同一个网页的图像,将会有大量的请求看上去几乎同样的,这就需要压缩技术对付这种几乎相同的信息。 - 随时复位
HTTP1.1一个缺点是当HTTP信息有一定长度大小数据传输时,你不能方便地随时停止它,中断TCP连接的代价是昂贵的。使用HTTP2的RST_STREAM将能方便停止一个信息传输,启动新的信息,在不中断连接的情况下提高带宽利用效率。 - 服务器端推流: Server Push
客户端请求一个资源X,服务器端判断也许客户端还需要资源Z,在无需事先询问客户端情况下将资源Z推送到客户端,客户端接受到后,可以缓存起来以备后用。 - 优先权和依赖
每个流都有自己的优先级别,会表明哪个流是最重要的,客户端会指定哪个流是最重要的,有一些依赖参数,这样一个流可以依赖另外一个流。优先级别可以在运行时动态改变,当用户滚动页面时,可以告诉浏览器哪个图像是最重要的,你也可以在一组流中进行优先筛选,能够突然抓住重点流。
参考资料
Http 0.9:http://www.w3.org/Protocols/HTTP/AsImplemented.html
Http 1.0:http://www.ietf.org/rfc/rfc1945.txt
Http 1.1:http://www.ietf.org/rfc/rfc2616.txt
Http 2.0:https://tools.ietf.org/html/rfc5741
Http Keep-Alive seems to be massively misunderstood. Here’s a short description of how it works, under both 1.0 and 1.1
HTTP/1.0
Under HTTP 1.0, there is no official specification for how keepalive operates. It was, in essence, tacked on to an existing protocol. If the browser supports keep-alive, it adds an additional header to the request:
Connection: Keep-Alive
Then, when the server receives this request and generates a response, it also adds a header to the response:
Connection: Keep-Alive
Following this, the connection is NOT dropped, but is instead kept open. When the client sends another request, it uses the same connection. This will continue until either the client or the server decides that the conversation is over, and one of them drops the connection.
HTTP/1.1
Under HTTP 1.1, the official keepalive method is different. All connections are kept alive, unless stated otherwise with the following header:
Connection: close
The Connection: Keep-Alive header no longer has any meaning because of this.
Additionally, an optional Keep-Alive: header is described, but is so underspecified as to be meaningless. Avoid it.
Not reliable
HTTP is a stateless protocol – this means that every request is independent of every other. Keep alive doesn’t change that. Additionally, there is no guarantee that the client or the server will keep the connection open. Even in 1.1, all that is promised is that you will probably get a notice that theconnection is being closed. So keepalive is something you should not write your application to rely upon.
KeepAlive and POST
The HTTP 1.1 spec states that following the body of a POST, there are to be no additional characters. It also states that “certain” browsers may not follow this spec, putting a CRLF after the body of the POST. Mmm-hmm. As near as I can tell, most browsers follow a POSTed body with a CRLF. There are two ways of dealing with this: Disallow keepalive in the context of a POST request, or ignore CRLF on a line by itself. Most servers deal with this in the latter way, but there’s no way to know how a server will handle it without testing.
https://tools.ietf.org/html/rfc7230#appendix-A.1.2
A.1.2. Keep-Alive Connections
In HTTP/1.0, each connection is established by the client prior to
the request and closed by the server after sending the response.
However, some implementations implement the explicitly negotiated
("Keep-Alive") version of persistent connections described in Section
19.7.1 of [RFC2068].
Some clients and servers might wish to be compatible with these
previous approaches to persistent connections, by explicitly
negotiating for them with a "Connection: keep-alive" request header
field. However, some experimental implementations of HTTP/1.0
persistent connections are faulty; for example, if an HTTP/1.0 proxy
server doesn't understand Connection, it will erroneously forward
that header field to the next inbound server, which would result in a
hung connection.
One attempted solution was the introduction of a Proxy-Connection
header field, targeted specifically at proxies. In practice, this
was also unworkable, because proxies are often deployed in multiple
layers, bringing about the same problem discussed above.
As a result, clients are encouraged not to send the Proxy-Connection
header field in any requests.
Clients are also encouraged to consider the use of Connection:
keep-alive in requests carefully; while they can enable persistent
connections with HTTP/1.0 servers, clients using them will need to
monitor the connection for "hung" requests (which indicate that the
client ought stop sending the header field), and this mechanism ought
not be used by clients at all when a proxy is being used.