BIOS和UEFI(都是用来引导操作系统的固件)
BIOS是Basic Input Output System的简称。它是位于计算机主板上的芯片中的低级软件。计算机启动时,BIOS加载,BIOS负责唤醒计算机的硬件组件,确保它们正常运行,然后运行引导加载程序来引导Windows或任何其他已安装的操作系统。
EFI,是Extensible Firmware Interface的词头缩写,直译过来就是可扩展固件接口,它是用模块化、高级语言(主要是C语言)构建的一个小型化系统,EFI和BIOS一样,主要在启动过程中完成硬件初始化,但它是直接利用加载EFI驱动的方式,识别系统硬件并完成硬件初始化,彻底摒弃读各种中断执行。EFI驱动并不是直接面向CPU的代码,而是由EFI字节码编写成,EFI字节码是专用于EFI的虚拟机器指令,需要在EFI驱动运行环境DXE下解释运行,这样EFI既可以实现通配,又提供了良好的兼容。此外,EFI完全是32位或64位,摒弃16位实模式,在EFI中就可以实现处理器的最大寻址,因此可以在任何内存地址存放任何信息。
当EFI发展到1.1的时候,英特尔决定把EFI公之于众,于是后续的2.0吸引了众多公司加入,EFI也不再属于英特尔,而是属于了Unified EFI Form的国际组织,EFI在2.0后也遂改称为UEFI,UEFI,其中的EFI和原来是一个意思,U则是Unified(一元化、统一)的缩写,所以UEFI的意思就是“统一的可扩展固件接口”。
UEFI就是BIOS的升级版,它最显而易见的区别在于它把把BIOS单调的蓝底白字或黑底白字替换为图文并茂的样式,可以通过鼠标点击进行设置,反正看起来就是很高大上的样子了。
BIOS和UEFI都包含了硬件驱动,不然怎么识别显示器和磁盘呢?
BIOS支持 16位,32位,64位系统,对系统安装没有限制。
efi固件只要支持64位,就绝对不会支持32位。反之同理。
UEFI固件64位的话,以UEFI启动只能安装7/8/8.1/10的64位系统,Legacybios启动安装一般没系统限制。现在新出台式机、笔记本多数取用新型主板,支持UEFI启动+Legacybios启动,UEFI固件绝大部分是64位。而平板电脑绝大部分UEFI固件32位,而且不支持Legacybios启动,这些平板只能UEFI启动安装8/8.1/10的32位系统.
Legacybios 是UEFI 的一个CSM 功能,Compatibility Support Module (CSM) that provides legacy BIOS compatibility.
MBR和GPT(都是分区格式)
正常情况下:BIOS 只识别 MBR ,UEFI 只识别 GPT,但是UEFI 有CSM模式,可以识别MBR。至于BIOS 呢,可以通过一定技巧识别GPT。
MBR只能支持4个主分区,再多就要用逻辑分区,而GPT则本身无限制,但受限于操作系统(Windows为128个);
MBR 与 GPT,都是分区格式,其中MBR最大分区小于等于2TB,而GPT分区没有2TB的限制,理论最大分区18 EB!GPT只能用在64位操作系统。Windows 10 64bit默认就是GPT。
MBR的硬盘最大支持2TB吗?不是说分区最大支持2TB嘛。MBR的4个主分区,加起来理论上应该可以支持8TB啊。【理论上可以实现接近4T,第一个分区2T不到点,第二个2T分区,因为有】https://superuser.com/questions/1393198/what-is-the-maximum-size-of-hard-drive-used-mbr-partitioning
MBR Sector 是什么
MBR Sector (Master Boot Record Sector) 是主引导记录扇区, 是硬盘上的第一个分区, 独立于其他文件系统。MBR 扇区 在磁盘上出现得比较多, 随着固件和硬件的发展, 将逐步被淘汰。
Master Boot Record Sector 是位于磁盘最前端的一段前导代码, 占一个扇区的空间大小, 因此被称为 MBR 扇区, 由于这一扇区承担有磁盘其他存储空间所不具备的特殊职能, 因此它独立于其他磁盘分区而存在。
- 位置: 磁盘 0 扇区 至 1 扇区
- 大小: 512Byte (1 扇区)
- 独立性: 不属于任何一个操作系统, 独立于所有磁盘分区, 不受其他磁盘分区操作影响

MBR Sector 的作用
保存磁盘主分区信息于 MBR Sector 的磁盘分区表中, 保存操作系统启动引导分区信息于 MBR Sector 的主引导记录中, 引导 BIOS 将控制权交给系统启动引导程序;
MBR Sector 的结构
MBR Sector 主要由三个部分组成:
- MBR 主引导记录, 保存操作系统启动引导信息
- DPT 磁盘分区表, 记录磁盘的主分区信息
- 结束标志, 值为
AA55, 为 MBR sector 的结束标志
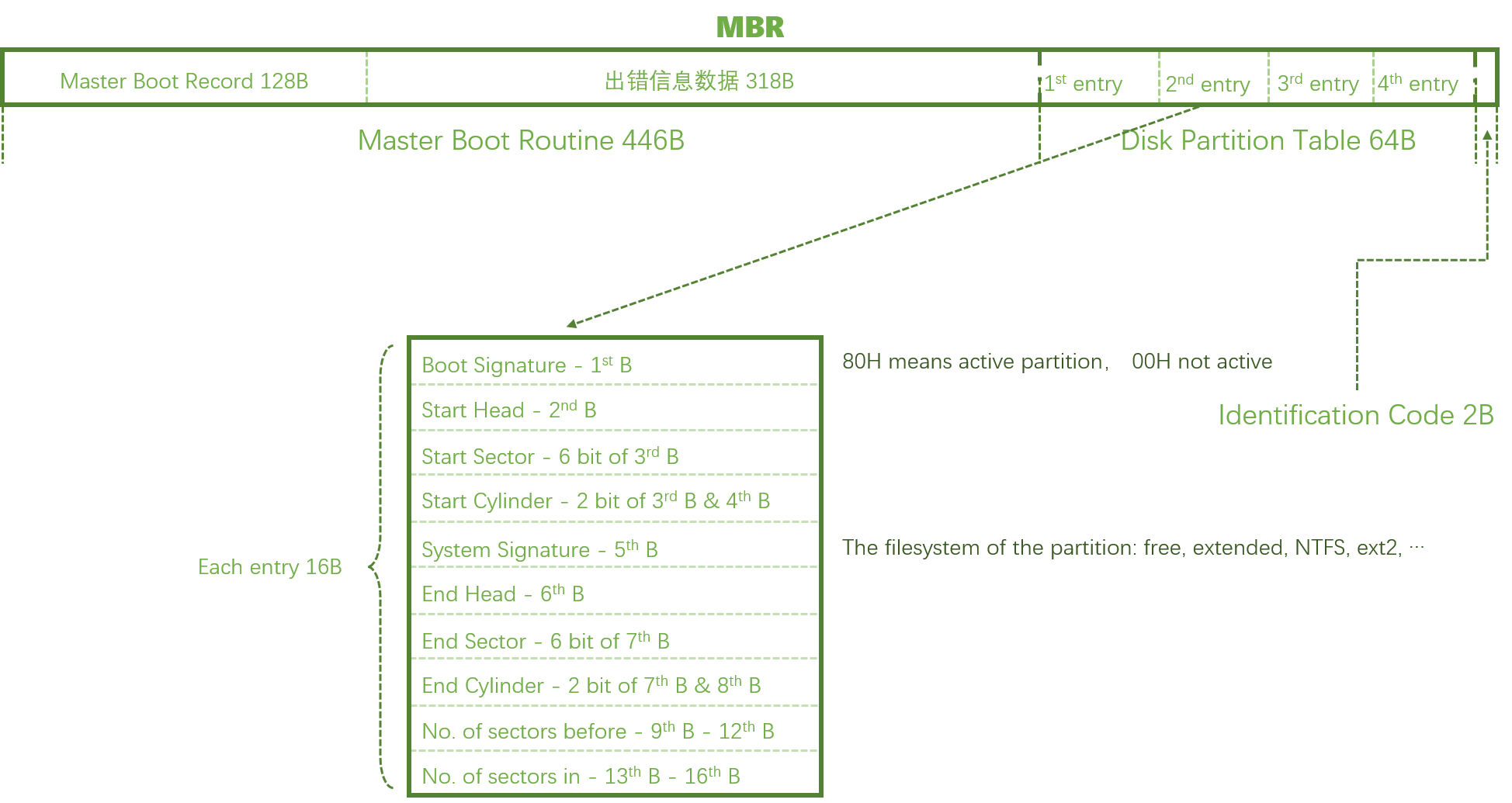
MBR 主引导记录
位置: 0000 – 01BD
大小: 446Byte
| 组成 | 位置 | 作用 |
|---|---|---|
| Master Boot Record | 0000 – 0088 | 引导代码, 引导从活动分区装载运行引导程序 |
| 出错信息数据区 | 0089 – 01BD | 记录数据, 0089 – 00E1 为出错信息, 00E2 – 01BD 为 0 字节 |
DPT 磁盘分区表
位置: 01BE – 01FD
大小: 64Byte
磁盘分区表占 64Byte, 中存储了 4 个主分区的信息, 每个分区信息占 16Byte, 因此, 使用 MBR Sector 的磁盘最多拥有 4 个主分区, 为解决主分区数量被绝对限制住的问题, 可将 16Byte 的数据拿来指向一个分区空间, 再在这个空间中进行独立分区和记录, 这个空间便被成为拓展分区, 拓展分区里的分区被称为逻辑分区, Linux 文件系统中对硬盘设备的命名规则与此相关
Linux FHS 对于磁盘/硬盘设备的命名为:
/dev/sd\[a-p]\[1-n]
sd 标识硬盘/磁盘设备文件,
a-p 代表 16块不同的硬盘, 从 a 开始分配,
1-4 代表主分区或者拓展分区, 5-n 代表拓展分区所指向的逻辑分区, 从 5 开始编号
DPT 结构信息
| 长度 | 意义 |
|---|---|
| 1 Byte | Boot Signature, 00 代表非活动分区, 08 代表活动分区 |
| 1 Byte | Start Head, 起始磁头 |
| 6 Bit | Start Sector, 起始扇区 |
| 10Bit | Start Cylinder, 起始柱面 |
| 1 Byte | Partiton Signature, 分区类型 |
| 1 Byte | End Head, 结束磁头 |
| 6 Bit | End Sector, 结束扇区 |
| 10Bit | End Cylinder, 结束柱面 |
| 4 Byte | Sector Preceding Partiton, 起始扇区地址 |
| 4 Byte | Sector in Partiton, 分区包含扇区数 |
结束标志
位置: 01FE – 01FF
大小: 2Byte
01FE 存储 55 标志, 为结束标志, 01FF 存储 AA 标志, 二者组合检验 MBR sector 是否有效。
参考:
https://blog.51cto.com/letitgo/1640956
https://zoharyips.github.io/2019/03/23/MBR/